
使用CUDA进行并行编程
颢匀
阅读:787
2024-04-13 22:31:34
评论:0
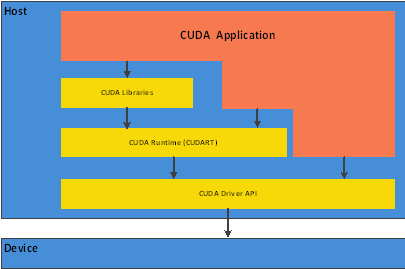
在使用CUDA进行并行编程时,首先需要了解CUDA是什么。CUDA是英伟达推出的并行计算平台和编程模型,可以利用GPU的并行计算能力加速应用程序的运行速度。下面将介绍如何使用CUDA进行并行编程:
1. 硬件要求
您需要一块支持CUDA的NVIDIA GPU。确保您的GPU支持CUDA并安装了最新的CUDA驱动程序。
2. 安装CUDA工具包
您可以从NVIDIA官方网站下载适用于您的操作系统的CUDA工具包,并按照官方指南进行安装。
3. 编写CUDA程序
使用CUDA进行并行编程需要编写CUDA C/C 代码。您可以使用CUDA提供的并行编程模型来编写核函数(kernels),并在主机代码中调用这些核函数。
```cpp __global__ void kernelFunction(float *input, float *output, int size) { int tid = blockIdx.x * blockDim.x threadIdx.x; if (tid < size) { output[tid] = input[tid] * 2; } } int main() { int size = 1000; float *h_input, *h_output; float *d_input, *d_output; // 分配内存并初始化数据 // 在GPU上分配内存 cudaMalloc(&d_input, size * sizeof(float)); cudaMalloc(&d_output, size * sizeof(float)); // 将数据从主机复制到设备 cudaMemcpy(d_input, h_input, size * sizeof(float), cudaMemcpyHostToDevice); // 调用核函数 kernelFunction<<<(size 255) / 256, 256>>>(d_input, d_output, size); // 将数据从设备复制回主机 cudaMemcpy(h_output, d_output, size * sizeof(float), cudaMemcpyDeviceToHost); // 释放内存 return 0; } ```4. 编译和运行
使用nvcc编译CUDA程序,并在支持CUDA的GPU上运行生成的可执行文件。
 ```bash
nvcc -o program program.cu
./program
```
```bash
nvcc -o program program.cu
./program
```
5. 优化CUDA程序
为了获得最佳性能,您可以考虑以下优化技巧:
- 合并数据传输操作,减少主机和设备之间的数据传输次数。
- 使用共享内存来减少全局内存访问。
- 优化线程块大小和网格大小以充分利用GPU的并行计算能力。
- 避免条件分支,尽量使核函数中的计算逻辑简单。
通过以上步骤,您可以开始使用CUDA进行并行编程,并利用GPU的并行计算能力加速应用程序的运行速度。








关注我们
扫一扫关注我们,了解最新精彩内容
