
堆栈在计算机语言的编译过程中用来进行语法检查
樊龙
阅读:352
2024-04-30 00:06:12
评论:0
在计算机编程中,栈和堆是两种用于管理内存的重要数据结构。它们在程序执行过程中扮演着不同的角色,了解它们的工作原理对于编写高效、可靠的代码至关重要。
栈(Stack)
栈是一种后进先出(LIFO)的数据结构,它主要用于存储局部变量、函数参数、函数调用和返回地址等。在程序执行过程中,每当一个函数被调用时,都会在栈中分配一段内存用于存储函数的参数和局部变量。当函数执行完毕时,这段内存会被释放。
栈的内存分配和释放是由编译器自动完成的,因此它的管理比较简单,但也比较有限。栈的大小通常是固定的,如果程序使用的栈空间超过了分配的大小,就会发生栈溢出(stack overflow),导致程序崩溃。
堆(Heap)
堆是一种用于动态分配内存的数据结构,它的大小不固定,可以根据程序的需求动态增长或缩小。在堆中分配的内存需要手动进行管理,包括分配和释放。
在编程中,通过堆可以实现动态数据结构,比如链表、树等,以及动态分配内存空间。但是,堆的管理比较复杂,容易出现内存泄漏(memory leak)和内存碎片化等问题,需要程序员自己来负责内存的分配和释放。
栈和堆的比较
| 特点 | 栈 | 堆 |
|---|---|---|
| 管理方式 | 编译器自动管理 | 手动管理 |
| 大小 | 固定 | 动态 |
| 分配速度 | 快 | 相对慢 |
| 生存期 | 函数调用期间 | 程序运行期间 |
| 管理复杂度 | 低 | 高 |
如何选择使用栈还是堆?
在编程中,选择使用栈还是堆取决于数据的生存期、大小和复杂度等因素。
- 使用栈:对于生命周期短、大小固定且较小的数据,比如局部变量和函数调用,通常选择使用栈。
- 使用堆:对于生命周期较长、大小不确定或动态变化,并且较复杂的数据结构,比如动态数组、对象等,通常选择使用堆。
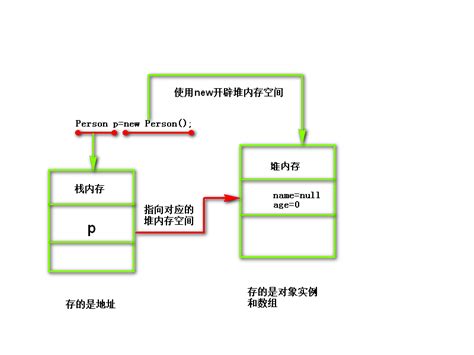
在实际编程中,合理地利用栈和堆可以提高程序的内存利用率和性能。对于堆内存的分配和释放要格外小心,避免出现内存泄漏和内存碎片化问题。








关注我们
扫一扫关注我们,了解最新精彩内容
